My Approach
Hi everybody,
After a bit of trial and errors on certain websites known to block the exit relays of Tor(reddit) found some interesting stuffs, that I didn’t know of.
Websites like Reddit (i) or Samsung shows error like: “503 Service Temporarily Unavailable” or “Access Denied” which concludes that these websites kind of blocks Tor fully. You could see the comment. Basically it lists my findings about reddit, it shows that one can access https://reddit.com using Tor, by logging in, tho one cannot remain anonymous after logging in, as the website knows the profile and gets quite some information, and that doesn’t remain anonymous browsing anymore. Though there are alternatives like: old reddit and reddit ssl that doesn’t require logging in and one can browse anonymously. But other websites like Instagram one needs to login in, to view the content.
Websites like Google (ii) loads without any restrictions, but searching up something, like maybe “Tor” Google Search Tor returns Captcha. Refer the image below:

There is also a specific case where the websites like: Lloyds Bank (iii) and Papa John’s Pizza which returns a website with 200 OKstatus code, but the webpage generally displays : “We are sorry an error has occurred, please try again later.” . This shows us that these websites are partially blocked over Tor.
Last but not the least, websites such as Github (iv) that doesn’t block Tor at all!
Above mentioned points can therefore be summarized into below 4 points. They are:
- Websites that don’t block Tor [iv]
- Websites that partially block Tor [iii]
- Websites that returns captchas [ii]
- Websites that completely block Tor [i]
Detailed Prospective:
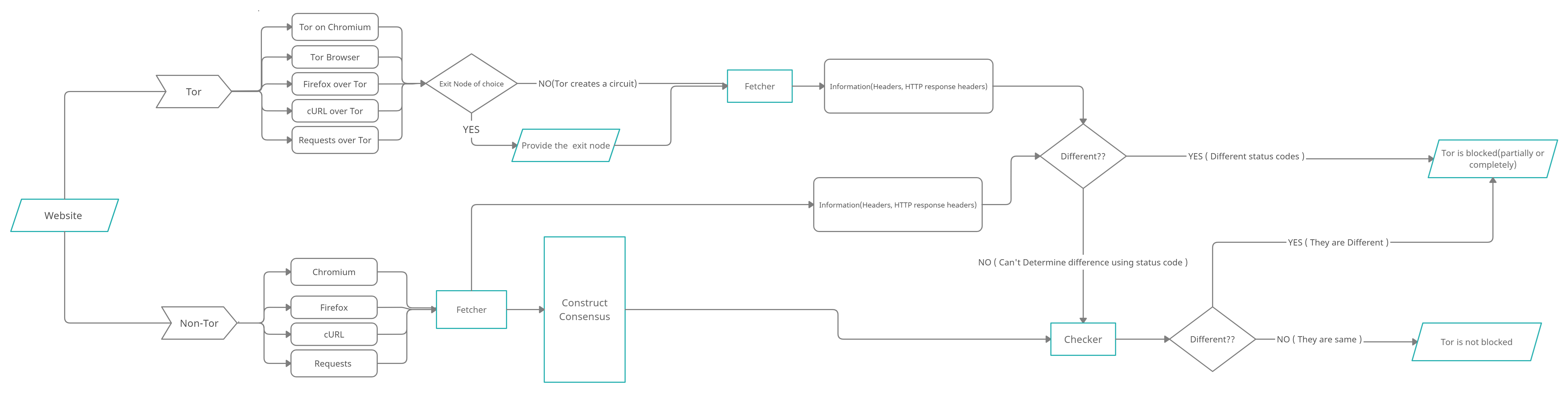
Below I’ve tried adding the low level flowchart, as well as the working and the logic part, that could be useful in the future.
The Overall Flowchart:
Working:
The main focus is to track the websites including Alexa Top 500 sites blocking Tor exit nodes fully or partially. So, a basic approach would be comparing the Http status codes, Headers (browser dependant or not), DOM Tree of a given website with Tor exit node and non-Tor exit node, but it might not always give the correct results. So I’ll be trying to categorize the results into cases and try to cover them all. Below I’m trying to broaden each path:
The non-Tor path is sort of a role-model path. We’ll compare the Tor path to this to find if there are any differences between the two paths, more extensively the tor exit nodes and browsers over tor to that of the non tor browsers. Since we are going to compare the information, we will save all the information that might help us with the comparison part. We are first going to fetch the Http headers, the http status codes, to get information of the websites (superficial-information) that might help to differentiate between the Tb [1] and Nb [2] without the need of scanning the whole website. We might achieve results easily for cases when status_code(Tb) != status_code(Nb):
Website Over Tor | Website not over Tor
——–|——–
 |
|  {Fig 1.1}
{Fig 1.1}
Or even in cases like these:
Website over Tor | Website not over Tor
——–|——–
 |
|  {Fig 1.2}
{Fig 1.2}
If for some reasons we cannot differentiate using the superficial information. Let’s say that the Tb and Nb return the same status codes status_code(Tb) == status_code(Nb) and we cannot determine the differences.
We next move to other options like:
- Compare the length of generated DOM from both Tb and Nb, which might work for a case below:
Website over Tor | Website not over Tor
——–|——–
 |
|  {Fig 1.3}
{Fig 1.3}
Here we can see that the status codes are 200, but still there is a clear difference between the results, and for the same reason I’m planning to compare the length.
-
Now, for such cases where there might be almost same length, we again cannot surely determine if the results are different. So we may approach it preparing the
consensusof each website. We parse the DOM elements into a tree type structure with hashes, calledSenserand collect the structure from all different NB we have (Chromium, Firefox, cURL, Requests) such that we get the picture of the unblocked-website we are looking for, and then accordingly get the results:-
If
Tb ≅ Nbwe know the Tor isn’t blocked. -
If
Tb != Nbwe know that the specific Tor fingerprint is blocked.
-
The Logic:
Below I’ve tried attaching the high-level Flow-chart that details about the process followed by the pseudocode.
HIGH LEVEL FLOW-CHART:

PSEUDO-CODE:
Tb = TOR(url) # fetch the url using Tor
Nb = BROWSER(url) # fetch the url using normal browser
if (status_code(Tb) != status_code(Nb)):
return false # either returns captcha or is blocked.
else:
if (DOM_len(Tb) << DOM_len(Nb)): # << denotes much larger than
return false # The Website might be partially blocked. e.g. Fig: 1.3
else:
p_c_t = prepare_consensus(Tb) # Prepare consensus using Tor.
p_c_n = prepare_consensus(Nb) # Prepare consensus using normal browser.
if (p_c_n == p_c_t):
return true # The Website is similar
else:
return false # The Website is not similar
Further Works and Ideas:
The ideas I will be aiming on are mentioned below, the basic idea for the Captcha Checker module has been discussed above.
- Working on the Senser paper (implementing a demo code to see how it works).
- Working on Dockers for easy-local installation.
- Working on the metrics and graphs related to the Dashboard.
- Also further experimenting on few cloudflare sites or maybe registering a cloudflare website (to get some better idea on how cloudflare works for Tor)
Refs: website 1, website 2, website 3
Tb [1] : Tor Browser
Nb [2] : Normal Browser
Senser paper could be accessed here and here’s the Webpage related to it.